Ranking
Node ranking
In ranking tasks, nodes obtain ordinal values 1,2,3,... based on their importance in the graph structure (1 is the most important node). To see how ranks can be obtained, load a graph and a community of nodes to test with. Below we define a personalized PageRank filter, which scores the structural relatedness of graph nodes to the ones of the given set, and apply a postprocessor that creates node ranks based on their score. Notice the time it took for the base ranker to converge. (Depends on backend and device characteristics.)
import pygrank as pg
_, graph, group = next(pg.load_datasets_one_community(["citeseer"]))
alpha = 0.85 # define this parameter to reuse the same value later
ranker = pg.PageRank(alpha=alpha, tol=1.E-20, max_iters=1000) >> pg.Ordinals()
ranks = ranker(graph, group)
print(ranker.convergence) # 70 iterations (0.012790299995685928 sec)
print(ranks) # {'100157': 107.0, '364207': 416.0, '38848': 626.0, 'bradshaw97introduction': 567.0, ... }
Robust stopping
We set an arbitrary desired numerical tolerance tol=1.E-20 because
we were unsure if smaller values would yield a robust node order;
we needed a very tight numerical tolerance to make sure.
On the other hand, the number of iterations can be reduced when
investigating node order convergence. In particular, we need
to define a different measure than
pg.Mabs, which is the default of the filter's convergence manager.
To stop at a robust node order,
we set a new measure of node score deviations between
consecutive PageRank iterations per
error_type=pg.OrderAccuracy. This is
is passed to the internally constructed convergence
manager. We keep the default tol=1.E-6. which
translates to stopping
iterations only when only 1/10,000 of nodes with adjacent tanks change order.
This time we find an earlier point in terms of the number of iterations.
However, pg.OrderAccuracy performs heavyweight sorting operations whose running
time grows \(O(n \log n)\) where \(n\) is the number of nodes. When compared to a
graph with an upper bound node degree, this sorting ends up being five times slower:
early_stop_ranker = pg.PageRank(alpha=alpha, error_type=pg.OrderAccuracy) >> pg.Ordinals()
fastranks = early_stop_ranker(graph, group)
print(early_stop_ranker.convergence) # 76 iterations (0.15961270000843797 sec)
print(pg.OrderAccuracy(ranks)(fastranks)) # 0.9996993385447985
Early stopping PageRank
We can instead estimate how premature the convergence should be
to stop the PageRank filter's diffusion at a robust enough node order.
To this end, we create a new convergence manager
to pass to the filter with the class pg.RankOrderConvergenceManager.
This manager stops at a diffusion step
where an equivalent random walk with restart process
would have accounted for a large percentage of random walks.
When stopped, pairs of nodes are set to not lose node order
with confidence=0.98.
Our code now stops much earlier and, importantly, the new
convergence criterion lets us enjoy the computational
speedups we would expect from early stopping:
convergence = pg.RankOrderConvergenceManager(pagerank_alpha=alpha, confidence=0.98)
smart_early_stop_ranker = pg.PageRank(alpha=alpha, convergence=convergence) >> pg.Ordinals()
fastranks = smart_early_stop_ranker(graph, group)
print(smart_early_stop_ranker.convergence) # 54 iterations (0.012241799995535985 sec)
print(pg.OrderAccuracy(ranks)(fastranks)) # 0.9882742032471438
Warning
In terms of asymptotic time complexity considerations, the variation we run above still performs sorting. However, it employs a mechanism of estimating when to check for stopping again, which means that the sorting happens very infrequently.
To avoid sorting completely and get a convergence manager with \(O(1)\) overhead
use the argument criterion='fraction_of_walks', as shown below.
This may stop a little too soon, given that it inserts a precomputed
number of iterations that arise from theoretical analysis. However,
it still accounts for the vast majority
of random walks and creates an empirically robust node order.
convergence = pg.RankOrderConvergenceManager(pagerank_alpha=alpha, criterion='fraction_of_walks')
smart_early_stop_ranker = pg.PageRank(alpha=alpha, convergence=convergence) >> pg.Ordinals()
fastranks = smart_early_stop_ranker(graph, group)
print(smart_early_stop_ranker.convergence) # 0.9882742032471438
print(pg.OrderAccuracy(ranks)(fastranks)) # 0.7269993986770896
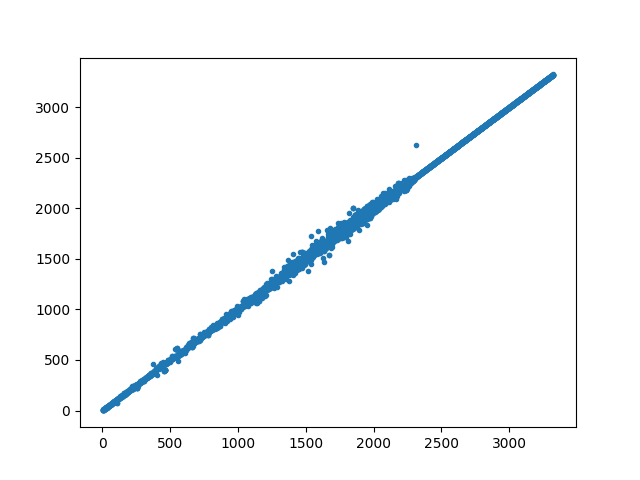
from matplotlib import pyplot as plt # install matplotlib separately, as it's not a pygrank dependency
plt.scatter(pg.to_numpy(ranks.np), pg.to_numpy(fastranks.np), marker='.')
plt.show()
Warning
pg.RankOrderConvergenceManager relies on theoretical
analysis that is applicable only to the pg.PageRank filter.
Furthermore, the pagerank_alpha parameter needs to
match the alpha parameter of the filter.